【15:10からリアルタイム配信 - R言語】7 規模効果の検証を例とした線形ファクター・モデル入門
2025/01/15
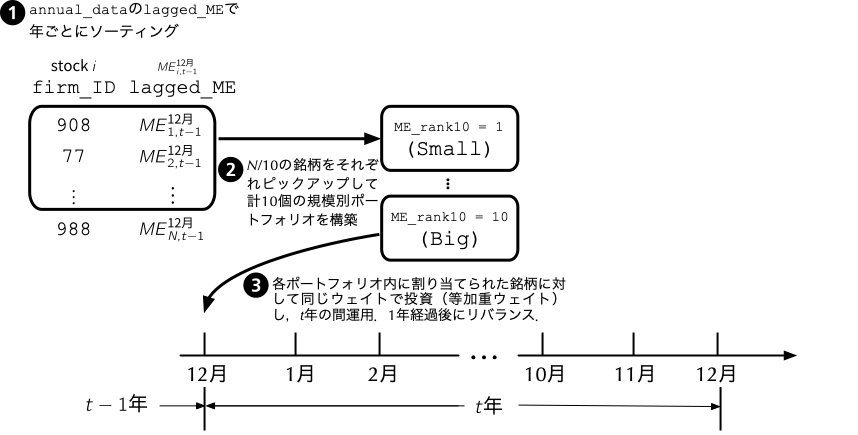
1 ポートフォリオ・ソート(教科書第6.1.2節)
1.1 時価総額によるポートフォリオ・ソート
- 何らかの特性に基づき各銘柄を順位付けて,その順位に基づいてポートフォリオを構築することをポートフォリオ・ソートと呼ぶ.
1.8 各ポートフォリオの平均超過リターンを棒グラフにより可視化してみよう!
Code
ME_sorted_portfolio %>%
group_by(ME_rank10) %>% # ME_rank10に関してグループ化
summarize(mean_Re = mean(Re)) %>% # 月次超過リターンの平均値を計算
ggplot() +
geom_col(aes(x = ME_rank10, y = mean_Re)) + # 棒グラフを描くにはgeom_col()関数を用いる
labs(x = "ME Rank", y = "Mean Monthly Excess Return") +
scale_y_continuous(expand = c(0, 0)) +
theme_classic()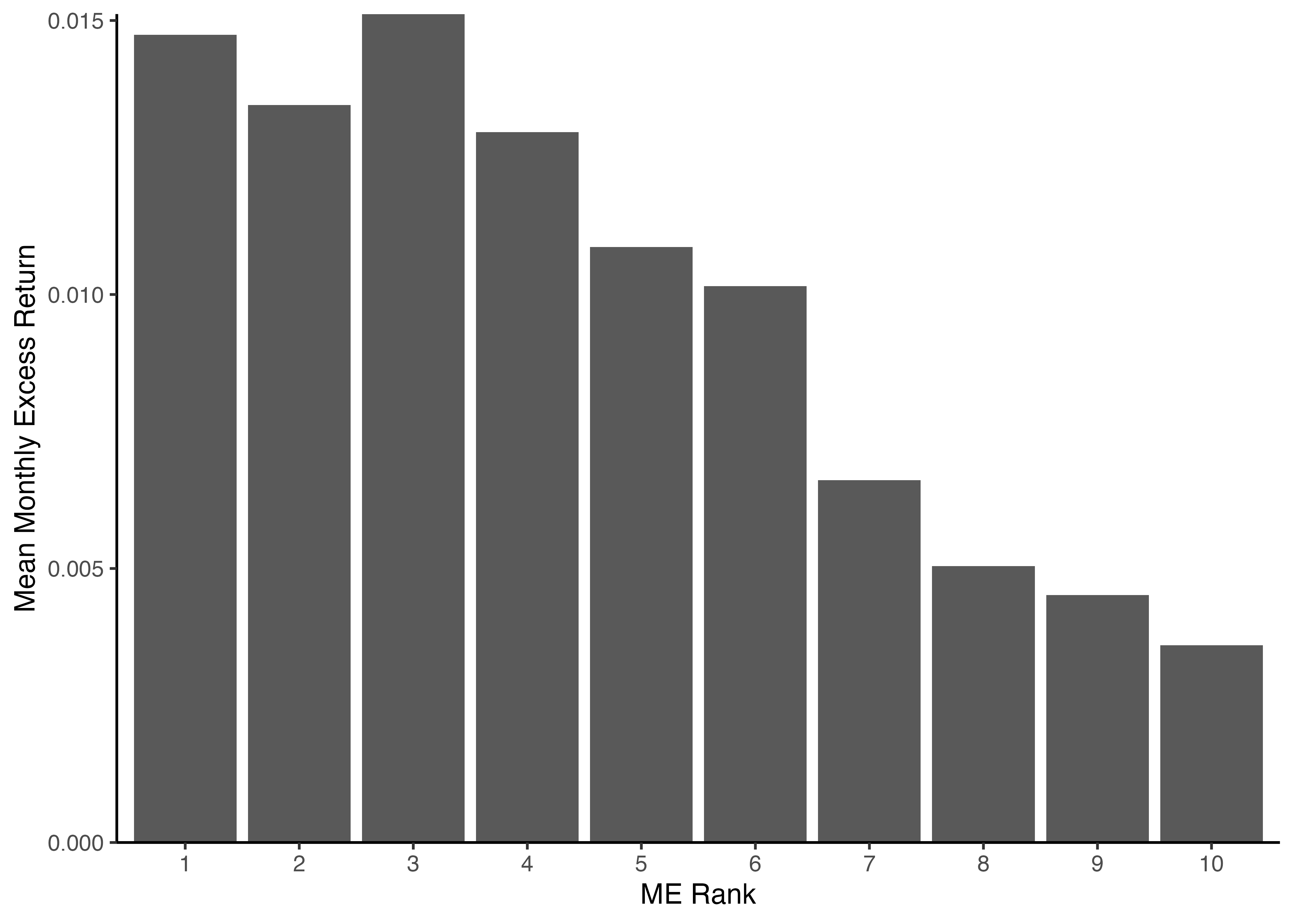
2.4 CAPMの実証的な検証
- CAPMは任意の資産に成立するものであり,個別銘柄の組合せであるポートフォリオにも応用できる.以降では,先に作成した時価総額で十等分したポートフォリオを検証対象としよう.
- これらのポートフォリオのリターンを次の回帰モデルで説明することを考える.
\[ \begin{align} R_{P,t}^e=\underbrace{\alpha_{P}}_{\substack{\textbf{CAPMが成立} \\ \textbf{すればゼロ}}} + \beta_{P}R_{M,t}^e+\varepsilon_{P,t} \label{eq:CAPM2} \tag{6.2} \end{align} \]
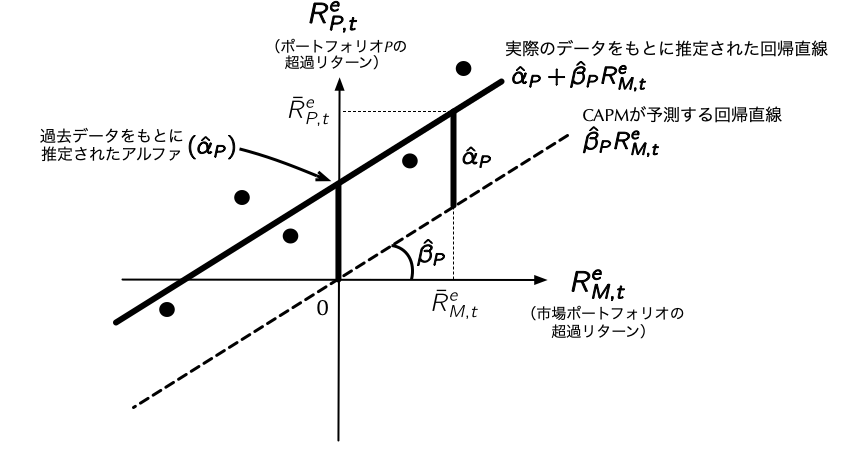
2.7 時系列回帰 — 概要
- ここでは手始めに時価総額が最小のポートフォリオ (
ME_rank10が1)のデータのみを抽出して,(\(\ref{eq:CAPM2}\))式を推定してみよう.これ時系列回帰 (time-series regression)といって,個々の銘柄やポートフォリオの実現リターンが市場ポートフォリオのリターンによってどの程度説明できるかを回帰したモデルである. - 時系列回帰のイメージは,下の図のとおりであり,任意のポートフォリオ\(P\)に関して,\(x\)軸には市場ポートフォリオの月次超過リターンを,\(y\)軸にはポートフォリオ\(P\)の月次超過リターンを取ったものである.
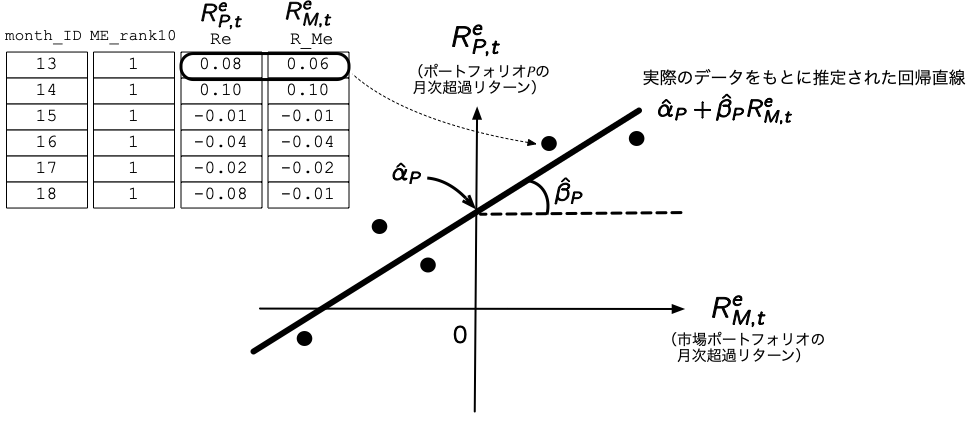
2.9 for文を用いた全ポートフォリオの推定

2.11 各ポートフォリオのCAPMアルファの可視化
- 最後に,定数項に関する推定結果のみを
filter()関数により抽出し,棒グラフにより各十分位ポートフォリオのCAPMアルファを描画してみよう.
Code
binded_CAPM_results %>%
filter(term == "(Intercept)") %>% # 定数項に関する推定結果のみを抽出
ggplot() +
geom_col(aes(x = ME_rank10, y = estimate)) + # 横軸をME_rank10, 縦軸をCAPM_alphaとする棒グラフ
geom_hline(yintercept = 0) +
labs(x = "ME Rank", y = "CAPM alpha") +
scale_y_continuous(limits = c(-0.003, 0.013)) +
theme_classic()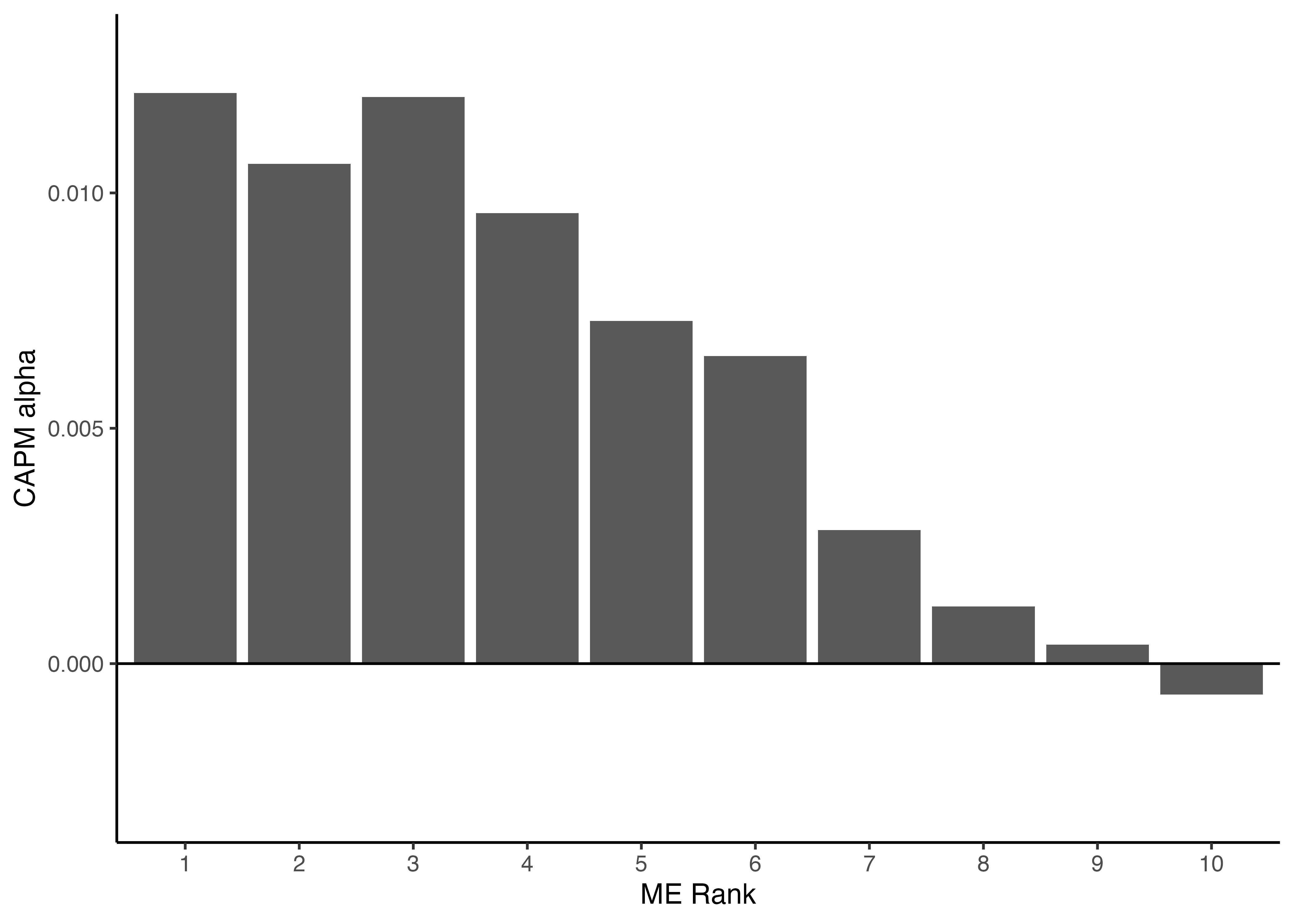
- 出力結果を見てみると,時価総額が小さいポートフォリオほど,
CAPM_alphが高いということが分かる.特に時価総額が最も小さいポートフォリオのCAPMアルファは1.21%で,年率に換算すると14.52% (\(=1.21% \times 12\))にもなる. - したがって,先に確認した実現超過リターンの傾向は,マーケット・ベータを調整済みのCAPMアルファでも存在することが分かる.
3.3 6 size-BE/MEポートフォリオ
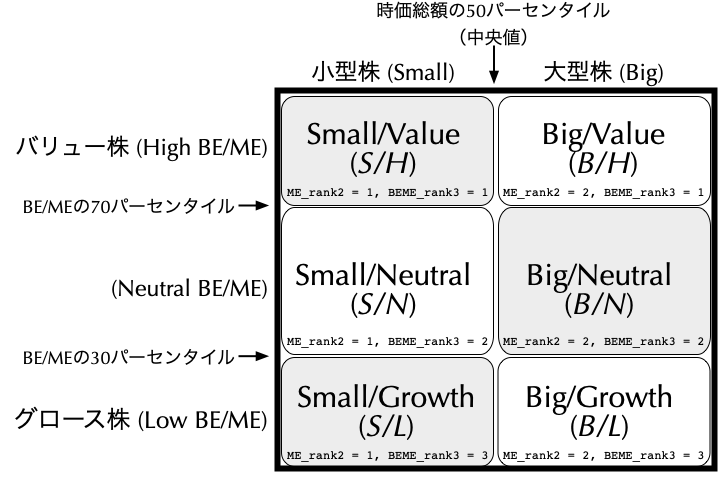
- 月次\(t\)の\(\mathit{SMB}\)を表す\(\mathit{SMB}_{t}\)は,次のように計算することができる. \[ \begin{align*} \mathit{SMB}_{t} = \underbrace{\left(\frac{\mathit{S/H}_{t}+\mathit{S/N}_{t}+\mathit{S/L}_{t}}{3}\right)}_{\textbf{小型株の平均リターン (\textcolor{red}{Small})}}-\underbrace{\left(\frac{\mathit{B/H}_{t}+\mathit{B/N}_{t}+\mathit{B/L}_{t}}{3}\right)}_{\textbf{大型株の平均リターン (\textcolor{red}{Big})}} \end{align*} \] ただし,右辺の各項は月次\(t\)における各ポートフォリオの月次リターンであり,例えば,\(\mathit{S/H}_{t}\)は\(\mathit{S/H}\)ポートフォリオの時価総額加重平均リターンを表す.
- 他方,月次\(t\)の\(\mathit{HML}\)を表す\(\mathit{HML}_{t}\)は,次のように計算することができる. \[ \begin{align*} \mathit{HML}_{t} = \underbrace{\left(\frac{\mathit{S/H}_{t}+\mathit{B/H}_{t}}{2}\right)}_{\textbf{バリュー株の平均リターン (\textcolor{blue}{High BE/ME})}}-\underbrace{\left(\frac{\mathit{S/L}_{t}+ \mathit{B/L}_{t}}{2}\right)}_{\textbf{グロース株の平均リターン (\textcolor{blue}{Low BE/ME})}} \end{align*} \]
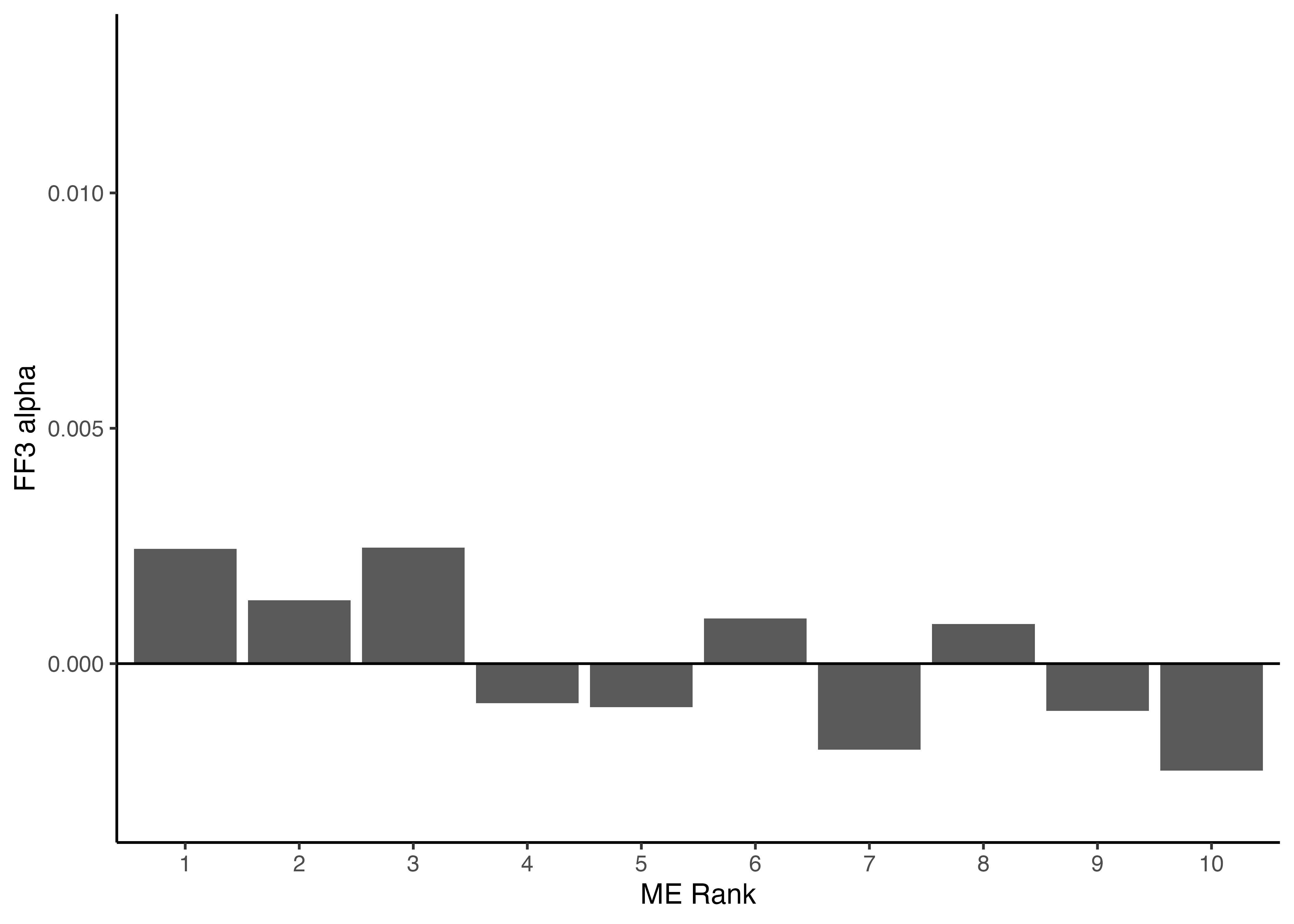
3.6 FF3アルファの可視化
- 先のスライドで
CAPM_alphaを図示した要領で,ポートフォリオごとにFF3アルファを描画してみよう. - 次スライドのコードでは,
binded_FF3_resultsから各ポートフォリオの定数項\(\hat{\alpha}_P^{\mathit{FF3}}\)を抽出した後,それを棒グラフで可視化している.
Code